You can create subset of data with your condition and then use shape or len:
print df col1 education 0 a 9th 1 b 9th 2 c 8th print df.education == '9th' 0 True 1 True 2 False Name: education, dtype: bool print df[df.education == '9th'] col1 education 0 a 9th 1 b 9th print df[df.education == '9th'].shape[0] 2 print len(df[df['education'] == '9th']) 2
Performance is interesting, the fastest solution is compare numpy array and sum:
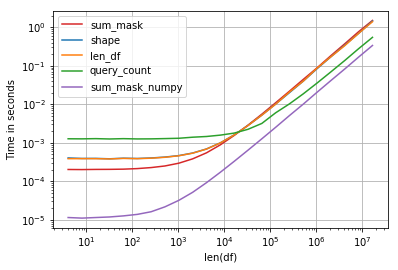
Code:
import perfplot, string
np.random.seed(123)
def shape(df):
return df[df.education == 'a'].shape[0]
def len_df(df):
return len(df[df['education'] == 'a'])
def query_count(df):
return df.query('education == "a"').education.count()
def sum_mask(df):
return (df.education == 'a').sum()
def sum_mask_numpy(df):
return (df.education.values == 'a').sum()
def make_df(n):
L = list(string.ascii_letters)
df = pd.DataFrame(np.random.choice(L, size=n), columns=['education'])
return df
perfplot.show(
setup=make_df,
kernels=[shape, len_df, query_count, sum_mask, sum_mask_numpy],
n_range=[2**k for k in range(2, 25)],
logx=True,
logy=True,
equality_check=False,
xlabel='len(df)')