as.factor is a wrapper for factor, but it allows quick return if the input vector is already a factor:
function (x)
{
if (is.factor(x))
x
else if (!is.object(x) && is.integer(x)) {
levels <- sort(unique.default(x))
f <- match(x, levels)
levels(f) <- as.character(levels)
if (!is.null(nx <- names(x)))
names(f) <- nx
class(f) <- "factor"
f
}
else factor(x)
}
Comment from Frank: it’s not a mere wrapper, since this “quick return” will leave factor levels as they are while factor() will not:
f = factor("a", levels = c("a", "b"))
#[1] a
#Levels: a b
factor(f)
#[1] a
#Levels: a
as.factor(f)
#[1] a
#Levels: a b
Expanded answer two years later, including the following:
- What does the manual say?
- Performance:
as.factor>factorwhen input is a factor - Performance:
as.factor>factorwhen input is integer - Unused levels or NA levels
- Caution when using R’s group-by functions: watch for unused or NA levels
What does the manual say?
The documentation for ?factor mentions the following:
‘factor(x, exclude = NULL)’ applied to a factor without ‘NA’s is a no-operation unless there are unused levels: in that case, a factor with the reduced level set is returned. ‘as.factor’ coerces its argument to a factor. It is an abbreviated (sometimes faster) form of ‘factor’.
Performance: as.factor > factor when input is a factor
The word “no-operation” is a bit ambiguous. Don’t take it as “doing nothing”; in fact, it means “doing a lot of things but essentially changing nothing”. Here is an example:
set.seed(0) ## a randomized long factor with 1e+6 levels, each repeated 10 times f <- sample(gl(1e+6, 10)) system.time(f1 <- factor(f)) ## default: exclude = NA # user system elapsed # 7.640 0.216 7.887 system.time(f2 <- factor(f, exclude = NULL)) # user system elapsed # 7.764 0.028 7.791 system.time(f3 <- as.factor(f)) # user system elapsed # 0 0 0 identical(f, f1) #[1] TRUE identical(f, f2) #[1] TRUE identical(f, f3) #[1] TRUE
as.factor does give a quick return, but factor is not a real “no-op”. Let’s profile factor to see what it has done.
Rprof("factor.out")
f1 <- factor(f)
Rprof(NULL)
summaryRprof("factor.out")[c(1, 4)]
#$by.self
# self.time self.pct total.time total.pct
#"factor" 4.70 58.90 7.98 100.00
#"unique.default" 1.30 16.29 4.42 55.39
#"as.character" 1.18 14.79 1.84 23.06
#"as.character.factor" 0.66 8.27 0.66 8.27
#"order" 0.08 1.00 0.08 1.00
#"unique" 0.06 0.75 4.54 56.89
#
#$sampling.time
#[1] 7.98
It first sort the unique values of the input vector f, then converts f to a character vector, finally uses factor to coerces the character vector back to a factor. Here is the source code of factor for confirmation.
function (x = character(), levels, labels = levels, exclude = NA,
ordered = is.ordered(x), nmax = NA)
{
if (is.null(x))
x <- character()
nx <- names(x)
if (missing(levels)) {
y <- unique(x, nmax = nmax)
ind <- sort.list(y)
levels <- unique(as.character(y)[ind])
}
force(ordered)
if (!is.character(x))
x <- as.character(x)
levels <- levels[is.na(match(levels, exclude))]
f <- match(x, levels)
if (!is.null(nx))
names(f) <- nx
nl <- length(labels)
nL <- length(levels)
if (!any(nl == c(1L, nL)))
stop(gettextf("invalid 'labels'; length %d should be 1 or %d",
nl, nL), domain = NA)
levels(f) <- if (nl == nL)
as.character(labels)
else paste0(labels, seq_along(levels))
class(f) <- c(if (ordered) "ordered", "factor")
f
}
So function factor is really designed to work with a character vector and it applies as.character to its input to ensure that. We can at least learn two performance-related issues from above:
- For a data frame
DF,lapply(DF, as.factor)is much faster thanlapply(DF, factor)for type conversion, if many columns are readily factors. - That function
factoris slow can explain why some important R functions are slow, saytable: R: table function suprisingly slow
Performance: as.factor > factor when input is integer
A factor variable is the next of kin of an integer variable.
unclass(gl(2, 2, labels = letters[1:2])) #[1] 1 1 2 2 #attr(,"levels") #[1] "a" "b" storage.mode(gl(2, 2, labels = letters[1:2])) #[1] "integer"
This means that converting an integer to a factor is easier than converting a numeric / character to a factor. as.factor just takes care of this.
x <- sample.int(1e+6, 1e+7, TRUE) system.time(as.factor(x)) # user system elapsed # 4.592 0.252 4.845 system.time(factor(x)) # user system elapsed # 22.236 0.264 22.659
Unused levels or NA levels
Now let’s see a few examples on factor and as.factor‘s influence on factor levels (if the input is a factor already). Frank has given one with unused factor level, I will provide one with NA level.
f <- factor(c(1, NA), exclude = NULL) #[1] 1 <NA> #Levels: 1 <NA> as.factor(f) #[1] 1 <NA> #Levels: 1 <NA> factor(f, exclude = NULL) #[1] 1 <NA> #Levels: 1 <NA> factor(f) #[1] 1 <NA> #Levels: 1
There is a (generic) function droplevels that can be used to drop unused levels of a factor. But NA levels can not be dropped by default.
## "factor" method of `droplevels` droplevels.factor #function (x, exclude = if (anyNA(levels(x))) NULL else NA, ...) #factor(x, exclude = exclude) droplevels(f) #[1] 1 <NA> #Levels: 1 <NA> droplevels(f, exclude = NA) #[1] 1 <NA> #Levels: 1
Caution when using R’s group-by functions: watch for unused or NA levels
R functions doing group-by operations, like split, tapply expect us to provide factor variables as “by” variables. But often we just provide character or numeric variables. So internally, these functions need to convert them into factors and probably most of them would use as.factor in the first place (at least this is so for split.default and tapply). The table function looks like an exception and I spot factor instead of as.factor inside. There might be some special consideration which is unfortunately not obvious to me when I inspect its source code.
Since most group-by R functions use as.factor, if they are given a factor with unused or NA levels, such group will appear in the result.
x <- c(1, 2) f <- factor(letters[1:2], levels = letters[1:3]) split(x, f) #$a #[1] 1 # #$b #[1] 2 # #$c #numeric(0) tapply(x, f, FUN = mean) # a b c # 1 2 NA
Interestingly, although table does not rely on as.factor, it preserves those unused levels, too:
table(f) #a b c #1 1 0
Sometimes this kind of behavior can be undesired. A classic example is barplot(table(f)):
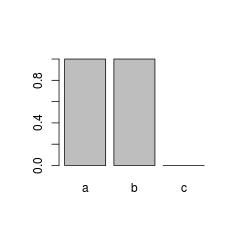
If this is really undesired, we need to manually remove unused or NA levels from our factor variable, using droplevels or factor.
Hint:
splithas an argumentdropwhich defaults toFALSEhenceas.factoris used; bydrop = TRUEfunctionfactoris used instead.aggregaterelies onsplit, so it also has adropargument and it defaults toTRUE.tapplydoes not havedropalthough it also relies onsplit. In particular the documentation?tapplysays thatas.factoris (always) used.