Summary
The following tests are meant to give some insights into the different approaches and should be taken with a grain of salt.
What is being tested here is not exactly generic filtering, but rather just applying a threshold, which has the notable feature that computing the condition is pretty fast. Very different results would be obtained if the condition would imply expensive computations.
Basically a 2-pass accelerated (either with Numba or Cython — as long as you know the types in advance) is going to be the fastest and more memory efficient, except for very large inputs, for which single pass Numba/Cython are faster (at the cost of larger temporary memory usage). Using np.where()/np.nonzero(), instead of the mask directly, may lead to slightly faster computation, and typically does not hurt (except perhaps for the larger temporary memory footprint) as long as the size of the output is less than 50% of the input. The np.fromiter() approach is much slower, but does not produce large temporary objects.
Definitions
- Using generators:
def filter_fromiter(arr, k):
return np.fromiter((x for x in arr if x < k), dtype=arr.dtype)
- Using boolean mask slicing:
def filter_mask(arr, k):
return arr[arr < k]
- Using
np.where():
def filter_where(arr, k):
return arr[np.where(arr < k)]
- Using
np.nonzero()
def filter_nonzero(arr, k):
return arr[np.nonzero(arr < k)]
- Using a Cython-based custom implementation(s):
- single-pass
filter_cy() - two-passes
filter2_cy()
- single-pass
%%cython -c-O3 -c-march=native -a
#cython: language_level=3, boundscheck=False, wraparound=False, initializedcheck=False, cdivision=True, infer_types=True
cimport numpy as cnp
cimport cython as ccy
import numpy as np
import cython as cy
cdef long NUM = 1048576
cdef long MAX_VAL = 1048576
cdef long K = 1048576 // 2
cdef int smaller_than_cy(long x, long k=K):
return x < k
cdef size_t _filter_cy(long[:] arr, long[:] result, size_t size, long k):
cdef size_t j = 0
for i in range(size):
if smaller_than_cy(arr[i]):
result[j] = arr[i]
j += 1
return j
cpdef filter_cy(arr, k):
result = np.empty_like(arr)
new_size = _filter_cy(arr, result, arr.size, k)
result.resize(new_size)
return result
cdef size_t _filtered_size(long[:] arr, size_t size, long k):
cdef size_t j = 0
for i in range(size):
if smaller_than_cy(arr[i]):
j += 1
return j
cpdef filter2_cy(arr, k):
cdef size_t new_size = _filtered_size(arr, arr.size, k)
result = np.empty(new_size, dtype=arr.dtype)
new_size = _filter_cy(arr, result, arr.size, k)
return result
import functools filter_np_cy = functools.partial(filter_cy, k=K) filter_np_cy.__name__ = 'filter_np_cy' filter2_np_cy = functools.partial(filter2_cy, k=K) filter2_np_cy.__name__ = 'filter2_np_cy'
- Using a Numba-based custom implementation
- single-pass
filter_np_nb() - two-passes
filter2_np_nb()
- single-pass
import numba as nb
import functools
@nb.njit
def filter_func(x, k):
return x < k
@nb.njit
def filter_nb(arr, result, k):
j = 0
for i in range(arr.size):
if filter_func(arr[i], k):
result[j] = arr[i]
j += 1
return j
def filter_np_nb(arr, k=K):
result = np.empty_like(arr)
j = filter_nb(arr, result, k)
result.resize(j, refcheck=False)
return result
@nb.njit
def filter2_nb(arr, k):
j = 0
for i in range(arr.size):
if filter_func(arr[i], k):
j += 1
result = np.empty(j, dtype=arr.dtype)
j = 0
for i in range(arr.size):
if filter_func(arr[i], k):
result[j] = arr[i]
j += 1
return result
filter2_np_nb = functools.partial(filter2_nb, k=K)
filter2_np_nb.__name__ = 'filter2_np_nb'
Timing Benchmarks
The generator-based filter_fromiter() method is much slower than the others (by approx. 2 orders of magnitude and it is therefore omitted in the charts).
The timing would depend on both the input array size and the percent of filtered items.
As a function of input size
The first graph addresses the timings as a function of the input size (for ~50% filtered out elements):
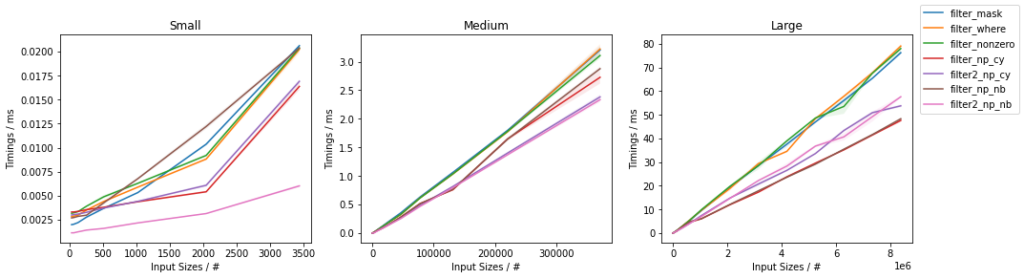
In general, the Numba based approaches are consistently the fastest, closely followed by the Cython approach. Within them, the two-passes approaches are typically fastest, except for very large inputs where the single-pass approach tend to take over. Within NumPy, the np.where()-based and np.nonzero()-based approaches are basically the same (except for very small inputs for which np.nonzero() seems to be slightly slower), and they are both faster than the boolean mask slicing, except for very small inputs (below ~100 elements) where the boolean mask slicing is faster. Moreover, for very small inputs, the Cython based solution are slower than NumPy-based ones.
As a function of filling
The second graph addresses the timings as a function of items passing through the filter (for a fixed input size of ~1 million elements):
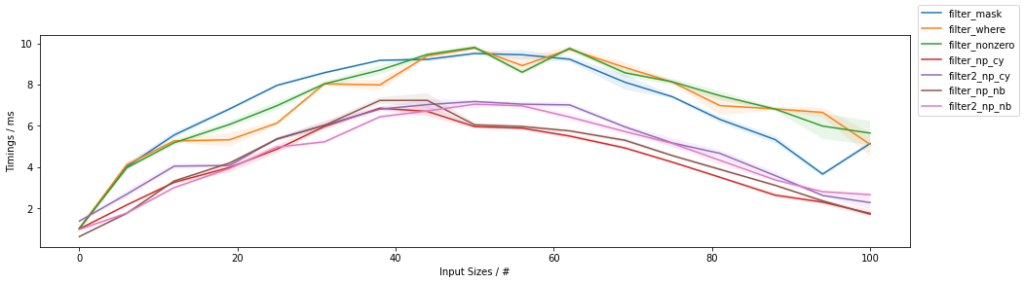
The first observation is that all methods are slowest when approaching a ~50% filling and with less, or more filling they are faster, and fastest towards no filling (highest percent of filtered-out values, lowest percent of passing through values as indicated in the x-axis of the graph). Again, both Numba and Cython version are typically faster than the NumPy-based counterparts, with Numba being fastest almost always and Cython winning over Numba for the outermost right part of the graph. The two-passes approaches have increasing marginal speed gains for larger filling values until approx. 50%, after which the single-pass take over the speed podium. Within NumPy, the np.where()-based and np.nonzero()-based approaches are again basically the same. When comparing NumPy-based solution, the np.where()/np.nonzero() solutions outperform the boolean mask slicing when the filling is below ~60%, after which boolean mask slicing becomes the fastest.
(Full code available here)
Memory Considerations
The generator-based filter_fromiter() method requires only minimal temporary storage, independently of the size of the input. Memory-wise this is the most efficient method. Of similar memory efficiency are the Cython / Numba two-passes methods, because the size of the output is determined during the first pass.
On the memory side, the single-pass solutions for both Cython and Numba require a temporary array of the size of the input. Hence, these are not very memory-efficient compared to two-passes or the generator-based one. Yet they are of similar asymptotic temporary memory footprint compared to masking, but the constant term is typically larger than masking.
The boolean mask slicing solution requires a temporary array of the size of the input but of type bool, which in NumPy is 1 bit, so this is ~64 times smaller than the default size of a NumPy array on a typical 64-bit system.
The np.nonzero()/np.where() based solution has the same requirement as the boolean mask slicing in the first step (inside np.nonzero()/np.where()), which gets converted to a series of ints (typically int64 on a 64-bit system) in the second step (the output of np.nonzero()/np.where()). This second step, therefore, has variable memory requirements, depending on the number of filtered elements.
Remarks
- the generator method is also the most flexible when it comes to specifying a different filtering condition
- the Cython solution requires specifying the data types for it to be fast, or extra effort for multiple types dispatching
- for both Numba and Cython, the filtering condition can be specified as a generic function (and therefore does not need to be hard-coded), but it must be specified within their respective environment, and care must be taken to make sure that this is properly compiled for speed, or substantial slowdowns are observed otherwise.
- the single-pass solutions require additional code to handle the unused (but otherwise initially allotted) memory.
- the NumPy methods do NOT return a view of the input, but a copy, as a result of advanced indexing:
arr = np.arange(100)
k = 50
print('`arr[arr > k]` is a copy: ', arr[arr > k].base is None)
# `arr[arr > k]` is a copy: True
print('`arr[np.where(arr > k)]` is a copy: ', arr[np.where(arr > k)].base is None)
# `arr[np.where(arr > k)]` is a copy: True
print('`arr[:k]` is a copy: ', arr[:k].base is None)
# `arr[:k]` is a copy: False
(EDITED: Included np.nonzero()-based solutions and fixed memory leaks and avoid copy in the single-pass Cython/Numba versions, included two-passes Cython/Numba versions — based on @ShadowRanger, @PaulPanzer, @max9111 and @DavidW comments.)